
When you’re starting on your coding journey, the question inevitably arises of “what are the fundamental concepts I need to know?” Well, data structures is one of them!
You don’t have to know every single detail there is to know about data structures, but it’s incredibly valuable to understand the basic types of data structures, their advantages and disadvantages, and when to use them.
In this special guest post, Ethan Urie of Learn to Be a Developer guides us through the data structures that every beginner developer should learn about.
Disclosure: I’m a proud affiliate for some of the resources mentioned in this article. If you buy a product through my links on this page, I may get a small commission for referring you. Thanks!
Here’s Ethan!
Have you ever felt like you’re totally missing a huge, important concept when you’re learning something new?
When you’re teaching yourself how to code or attending a coding bootcamp, you’ll often feel a bit uneasy or inadequate when it comes to certain concepts. Heck, I still feel that way sometimes and I’ve been coding for years.

The two concepts that seem to cause the most feelings of inadequacy in beginners are data structures and algorithms. These two topics typify a computer science education to those who don’t have one. Given the title of this post, naturally, I’ll be talking about data structures. If you haven’t started your self-teaching (or other means, I’m not judging) journey yet, this post might help you get started.
In all honesty, however, you probably don’t have to dive into the nitty-gritty details underlying each data structure. What you should aim for is to have a good understanding of what data structures are, which ones are “must-know,” be familiar with some uncommon ones, and know how to compare them so you pick the best solution.
This will be particularly helpful when it comes to sitting technical interviews as part of your job hunt.
So, What the Heck Are Data Structures Exactly?
The “tl;dr” version is that data structures are ways to store data. Simple, right? But what does that actually mean?
Okay, so one of the first things you learn when starting to code is how to store data, usually a simple value like a string or number, in a variable. As their name implies, the value that a variable contains can be changed, or varied — see what I did there? Constants are like variables because they store a value, but can’t be changed. I’ll spare you the snark this time; it was too obvious.
So if variables and constants store data, why aren’t they data structures?
It’s because data structures can hold more than a single value, organize that data, and allows you, dear developer, to perform operations on them. This allows you to keep the data together as you pass it around your program and do different things with it.
How Do I Pick the Right Data Structure?
So data structures help you store multiple values, right? What’s special about that?
The way you contain and organize your data helps determine how easily you can do certain tasks. We all like it when things are easier to do, right? I do.
Generally, the tasks you’ll want to do on your data are:
- Add some
- Remove some
- Find some
- Sort it all
Depending on which of these tasks you’re going to want to do most, you will choose a data structure that makes that task easier, faster, and more efficient.
The characteristics of data structures that most often influence these tasks are how the data structure lays out its data in the computer’s memory. In object-oriented programming, we usually think in terms of objects and how certain objects relate to, or use, other objects. The same goes for data structures but here the “objects” are items (data values) that the structure stores and how those are related or connected to other items in the same structure.
The other primary data structure characteristic you’ll want to look for is how the data structure organizes its data. This impacts how easy and quick it is to find what you’re looking for, and can also affect how easy it is to add or remove data.
When you understand these characteristics and how they trade-off between themselves, you will gain the ability to find and pick the right data structure for the right task. In the end, this will mean your programs will be simpler, easier to understand and write, and more efficient, either in memory usage or performance.
Onward!
The 4 Data Structures Beginner Developers Should Know
There are ton of data structures that have been created and they all have their pros and cons. In general though, thankfully, there are four main structures that every developer should know and all new developers should learn early on.
Three of these structures — linked lists, arrays, and dictionaries — are linear, or 2-dimensional, in nature. In other words, they grow and shrink in length only.
The last structure, trees, grows and shrinks in length and depth. Like real trees, but different. Confusing? Just wait, you’ll see.
1. Linked Lists
Linked lists are the simplest of the four data structures we’ll talk about.
You can visualize a linked list as a chain. The links of the chain are the items in the linked list, called nodes. Each node is connected to the node in front and the node behind (except for the first and last nodes, obviously). Other than that, there is very little that each individual node does.
The simplest version of the linked list has only one connection between nodes: the connection to the next node. This is a singly-linked list.
Given that each node is only connected to the next node in the list, you can only walk through (or traverse) the list from the beginning to the end, never backwards.
In code, you will have a reference, in a variable, to the first node. This is the head of the list. You can then use that reference to walk through the list, calling a method like nextNode() or just next() on each node.

More advanced versions of linked lists will also have a reference to the last node in the list, often called tail. In a singly-linked list, this reference only helps to add links to the end of the list so it isn’t usually used. The tail reference becomes much more useful in doubly-linked lists.
I’ll give you one guess what’s different about doubly-linked lists.
Right-O, doubly-linked lists are doubly-linked. Gosh, those clever, clever developers and their naming.
As you might have already guessed, doubly-linked lists have two connections between nodes. One connection is to the node before, and one connection is to the node after. This allows you to traverse the list in both directions. Handy dandy!
Why would anyone use a singly-linked list then if doubly-linked lists exist and make life easier? Well, it’s a trade-off.
In this case, the trade-off is with memory usage. If each node has two links, one to the preceding node and one to the following node, you double the amount of node references used by a list. This may not seem like a big deal when talking about web-scale applications, but it is important when thinking about embedded and even mobile applications where there’s less memory to use.
So why would you choose a linked list?
And why wouldn’t you?
And, if you did choose one, why would you pick a singly-linked list over a doubly-linked one?
Well, dear reader, let me explain.
Advantages of Linked Lists
Linked lists are pretty simple. This means that they’re easy to create if you need to make your own. They also only take up enough memory to hold each item in the list and a reference to the next one, for a singly-linked list. For doubly-linked lists, like I mentioned above, there’s another reference to the previous link. This all means that linked lists are relatively memory-efficient. There’s very little wasted space. You’ll see how this differs when we cover the next two data structures.
Linked lists are also easy to add and remove data from because you merely have to:
- find the spot in the list
- create a new node
- assign the new node’s next reference to the next node
- assign the current node’s next reference to your new node.
Snip, snip, snip.
If you’re appending to the end and have a tail reference, it’s even easier because there’s no traversal.
Disadvantages of Linked Lists
Rarely is there a data structure that only has upsides. Linked lists are no exception.
Because you access items in a linked list by starting at one end and working towards the other end, searching for a specific item can take a long time, relatively speaking. In the worst case, you start at one end and the item you’re looking for is on the other end. This means that the amount of time to find any specific item depends on how long the list is. The longer the list, the longer the average time is to find a specific item. For those interested, this is what Big-O notation is for: discussing the efficiency of these kinds of operations as the amount of data grows.
Building on the poor efficiency of searching linked lists, sorting them is also slow. This follows because to sort, you have to take each item in the list and compare it to the others, then insert it in the right place. Constantly working from one end towards the other means that you traverse the list many, many times.
When to Use a Linked List
You can use a linked list when:
- memory usage is a concern
- searching and sorting does not have to be fast (or necessary)
- the data is conceptually connected linearly
2. Arrays
Arrays are the next level after linked lists. Instead of each item being connected to the next one (and maybe the previous one) there is no direct connection between items in arrays.
Let’s get our mental model started: Where linked lists are kind of like chains, arrays are like a weekly pill organizer that a lot of elderly people have to organize their medication.
If you’re not familiar with them, the organizers have seven small containers, all lined up horizontally, one for each day of the week and marked with the day’s first letter. All of the individual containers are connected in a line.
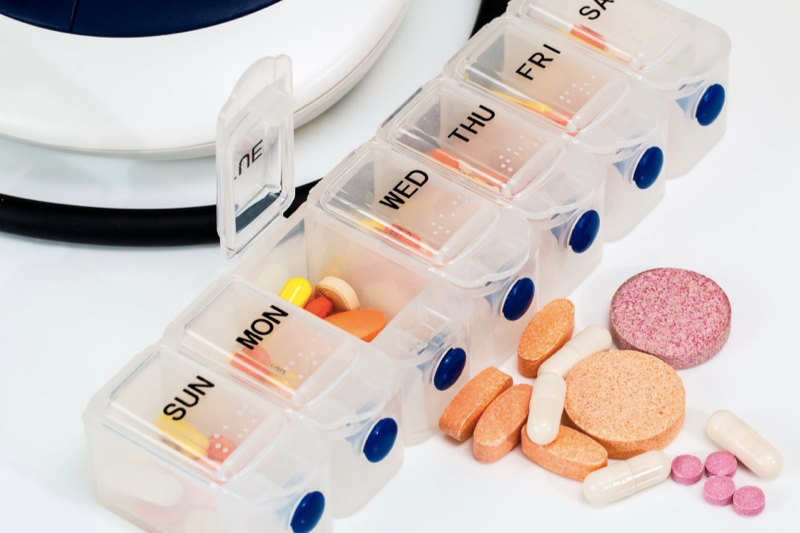
This is how arrays are laid out in memory. When you create one, a chunk of contiguous memory is set aside for it. In statically-typed languages like C++, Java, C# the amount of memory that’s set aside is based on the type of values to be stored inside the array. For dynamic languages like Python and Ruby, the arrays are allocated based on those languages’ basic objects, which can handle all types.
Instead of starting at an end of an array and traversing it to find the item you want, you access items by their index, i.e., what number place they hold in the array. This index is actually accessing a specific location in the block of memory allocated for the array.
Because the index are locations in the memory block, they are zero-based. The index number is essentially the number of the item you want from the beginning of the array. So the first item in the array is accessed by index 0. It’s the first item plus 0 more. This also means that the last item is at the index of the total number of items, minus one (i.e., n – 1 where n is the total number of items).
Accessing a specific item in an array is very fast if you know the index. In fact, accessing a specific item, with a known index, is constant. It stays the same regardless of the number of items in the array.
If you don’t know the index of the item you want, you have to traverse it like linked lists. The only difference is that you don’t have reference to the next item in an array, so you have to loop over all the possible index values. This is where security issues can come in with languages like C and C++, where it’s possible to go past the end of an array. If you do this, you’ll be reading data belonging to some other object or program.
Advantages of Arrays
Arrays can be accessed very quickly if you know the index(es) you need. Because indexes don’t change as you insert or remove data, the speed at which you access any specific item remains the same regardless of how long the array is.
Disadvantages of Arrays
On the downside, arrays can be slow and inefficient when you need to resize them. Because they are contiguous blocks of memory, you have to create them with the size you expect to need. If you misjudge this and ask for too little memory, then when you reach the end, the array needs to be resized.
What does resizing an array mean, practically speaking? It means that a new, larger block of memory needs to be allocated for the new copy of the array. Then all the items from the original array must be copied to the new one. This is not fast, and for a time during the resize, you will use much more memory than the array really needs.

On the chance that you asked for too much memory at the beginning, you won’t have to resize it, but you will be wasting that extra memory. Some languages will default to certain sizes that should fit most uses, but will still probably waste a large percentage of the space in the end.
The problem with having to copy data from one array to a new array also exists for adding and removing data. Because arrays are made from contiguous blocks of memory and you access items using their index into that memory, if you want to add or remove some data from the middle, the remaining items have to be moved. This can be slow and inefficient, as you might expect.
When to Use an Array
In general, you should think about using an array when you:
- want immediate access to items and will know their index
- have a fairly stable number of items, or know a maximum number beforehand
- need to sort and search quickly
- won’t need to insert or remove data frequently
3. Dictionaries (Hash Tables)
As the name implies, this data structure lets you look up a value based on some other value. In coding terms, we use a key to look up a value. Each value is stored in the dictionary in a location associated with the key. The key is usually a string, but can be something else depending on the programming language and the implementation. Some languages, like Java, allow any object to be a key as long as it implements a hashCode() method, which returns a number.
A hash code, or hash, is a number that is mathematically derived from the object or string (like by using a hashCode() method). The hash code is then used as an index into the dictionary much like an index in an array. This is why these structures are also called Hash Tables or Hash Maps.
Advantages of Dictionaries
Looking up, adding, and removing data is very fast for dictionaries, as long as you know the keys. In fact, dictionaries are as fast as arrays because you don’t have to traverse them to find a value.
Because you can store values under a specific key, dictionaries are helpful to use when finding duplicates — check if the item is already in the dictionary, add it if it isn’t, or move on if it is. You can even set the number of times you’ve seen a value as the value in the dictionary.
You don’t run into the problems of inserting or removing data as much like in arrays because dictionaries are sized to minimize collisions between keys. To do this, dictionaries are relatively large and usually mostly empty.
Disadvantages of Dictionaries
If you don’t know the key or keys of the values you want, you have to traverse the dictionary from the beginning to the end. Most implementations that I’ve seen allow you to do this by giving you a list or array of the keys, and sometimes the values.
However, I have also seen some implementations that don’t give you any way to get all the keys or values from the dictionary.
If you can get the list of keys or values, you have to walk through that list much like walking through an array. The more keys and values are in the dictionary, the longer it will take to find the one(s) you want.
Another downside to dictionaries is that you can waste a lot of memory if you make a large one and don’t use much. Like a too-large array, a sparsely-populated dictionary wastes memory. In general, though, like arrays, dictionaries are sized overly large to maximize speed and minimize the need to handle key collisions or resizing.

Furthermore, if the hash codes that the implementation creates have a lot of collisions, performance and efficiency will drop because it will resolve those collisions. Some implementations will put all values whose keys collide into a “bucket,” which is usually an array.
If the hashing function used to create the keys is poor, or if the dictionary is too small, you can have a lot of collisions. If every key collides, you will end up with a dictionary with one entry and it will have to search through the bucket just like searching through an array.
Dictionaries are typically not meant to store sorted data, and most don’t provide any method of doing that.
Furthermore, if you do end up filling up a dictionary, it will have to be resized just like an array, except that each hash key will have to be recreated to take the new size into account. This can be relatively expensive time-wise.
When to Use Dictionaries
Dictionaries are most helpful when you have some kind of association, like when you have a constant or symbol that can be associated with a value that may change or is not known. Configuration values are helpful to store in dictionaries.
They are also very good for when you need to:
- look up values instantly and the keys are known
- avoid duplicate values
- store a stable amount of data
- store unsorted data
4. Trees
Trees are also what they sound like: structures that start at a root and then branch and spread out. The tree data structure, though, is often depicted as starting at the top and growing downward — think of roots beneath the ground. Like linked lists, trees have nodes that can contain values as well as references to its children nodes.

Tree nodes can have any number of children nodes, though a common number is two. Trees, where all nodes have a maximum of two nodes, are called binary trees.
Typically, trees are used for data that you want to be kept sorted and/or has a hierarchy. In binary trees, when kept sorted, the left child node’s value is less than the parent node’s value and the right child node’s value is greater. This way, it is very quick and easy to find a specific value without comparing against all of the possible values.
Advantages of Trees
Trees keep data sorted and make finding data very fast. Even so, finding a value is not as fast as in an array or dictionary when you know the index or key respectively. Whereas getting a value from an array or dictionary is the same regardless of how much data is stored, getting values from trees does take longer as the tree grows.
That said, as the tree grows, searching slows down less and less. I.e., as the tree gets bigger, searching is less affected by the change in size. This is because as you search, you’re eliminating half of the children nodes (on average) from the current node on. What that means is that trees are efficient for searching large amounts of data, because you only look at a fraction of the nodes.
Adding and removing data from trees is also quick since you just set and change the appropriate children node references like in linked lists. There is a caveat though, which I’ll get into in the disadvantages below.
In terms of memory, trees are fairly efficient because they only allocate enough to store the values in the nodes and references between those nodes. Arrays and dictionaries have to reserve large chunks of memory to avoid resizing, but trees do not.
Disadvantages of Trees
On the flip side of the memory argument, like linked lists, trees have to use memory to keep the references to children nodes. This is potentially higher than a linked list’s memory usage, depending on how many children nodes there are per node.
Another disadvantage of trees, which I hinted at above, is that to remain efficient for searching, the tree has to be balanced. By balanced, I mean that every node should have the same number of children nodes. That’s the ideal case. In reality, there will be some nodes with only one or even zero children, but there should not be many of them.

Furthermore, remember when I talked about a dictionary where all the keys collide and the values get put into a list that has to be searched from start to finish? When a tree is unbalanced, in the worst case, you end up with every node having only a single child node. In this case, you end up with a linked list and we all know how efficient they are to search — not very.
So rebalancing a tree is an important step. Unfortunately, it can be expensive in memory usage and time-consuming to do. Thankfully, there are tree variants that can keep themselves balanced. While that does not eliminate the cost of performing the rebalancing, at least you don’t have to do it.
One last disadvantage with trees is that while they’re fast to access, they aren’t as fast as arrays and dictionaries.
When to Use a Tree
Trees are great for storing unknown amounts of data that needs to be sorted and searched quickly. If the data will change often and still remain easily searched, trees are a great option. As long as you don’t need instant access to values, and can settle for fast, trees are good. The only real requirement is that you have data that can be sorted. For this reason, trees are not very good for storing data of different types that can’t be compared.
And That’s Data Structures!
That’s it. That’s a gentle introduction to four of the most important data structures every beginner developer should learn.

So, do you remember that feeling I mentioned at the very beginning? The one where you feel inadequate as a developer because you don’t understand some major concept?
Yeah, I know it’s still there, but I hope that this post has helped you take a much-needed step towards understanding data structures and overcoming that feeling of inadequacy.
You should now feel more confident in knowing when to use each data structure, or at least knowing what to look for when making a decision. I encourage you to practice with each of these common data structures. Practicing will give you a feel for which ones work better in different situations and make you a better, more confident developer.
Where to Learn More About Different Data Structures
Disclosure: I’m a proud affiliate for some of the resources mentioned in this article. If you buy a product through my links on this page, I may get a small commission for referring you. Thanks!
Introduction to Data Structures – Team Treehouse
In this course, you’ll learn about arrays, linked lists, common operations, and how the runtimes of these operations affect your everyday code. You’ll bring your knowledge of algorithms and data structures together to solve the problem of sorting data using the merge sort algorithm.
Programming Foundations: Data Structures – LinkedIn Learning
This course provides an in-depth overview of the most essential data structures for modern programming. Each lesson is accompanied by a real-world, practical example that shows the data structures in action.
Data Structures and Algorithms Specialization – Coursera
This specialization is a mix of theory and practice: you will learn algorithmic techniques for solving various computational problems and will implement about 100 algorithmic coding problems in a programming language of your choice.
Data Structures – Coursera
This course is part of the Specialization above. You’ll consider the common data structures that are used in various computational problems, and learn how these data structures are implemented in different programming languages.
The Ultimate Data Structures & Algorithms Course – Code With Mosh
This course teaches you everything you need to know about data structures and algorithms so you can ace your coding interview with confidence. It’s a perfect mix of theory and practice, packed with over 100 popular interview questions.
About the Author

Ethan Urie is a professional software developer with over 15 years of experience in a variety of industries. He loves learning new programming languages, frameworks, and technologies. He also loves teaching what he’s learned to others and helping them become professional developers themselves. He writes posts and guides for aspiring developers on his blog learntobeadeveloper.com.